Onlangs kwam in het nieuws dat het bedrijf Cambridge Analytica de Facebookgegevens van vijftig miljoen Amerikanen voor de afgelopen verkiezingen gebruikte om de content van Facebook in het Republikeinse spoor te trekken. Sindsdien weten we als het grote publiek van het bestaan van ‘big data’. Hoe voorkomen we dat die data met ons aan de haal gaan en hoe worden we die data de baas? Bernard Veldkamp neemt ons aan de hand.
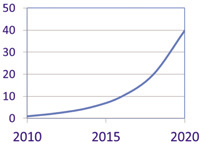
Vandaag de dag worden we overspoeld met data. Mobiele telefoons, het internet, zoekmachines, webshops, social media, klantenkaarten, pinbetalingen, smart homes en bijvoorbeeld smartwatches genereren een enorme massa aan data, die opgeslagen wordt op servers. Al deze data leggen vast hoe personen, maar ook machines of systemen zich gedragen. De hoeveelheid data neemt bovendien exponentieel toe. Om de grootte van de datamassa te illustreren een paar getallen. Een hoeveelheid informatie wordt vaak weergegeven in bytes. Een foto is bijvoorbeeld 3 Mb, oftewel 3*106 bytes. Tot en met 1999 kwam de totale beschikbare hoeveelheid data, alles wat er geschreven, gepubliceerd en opgeslagen was, overeen met 2Eb. 2Eb is 2*1018 bytes. In 2010 was de totale beschikbare hoeveelheid informatie gelijk aan 1 Zb, dat is 1*1021 bytes. Sindsdien blijft die hoeveelheid exponentieel stijgen. Elk jaar komt er ca. veertig procent bij. Die toename wordt weergegeven in Figuur 1.
Deze data worden niet alleen verzameld, maar ook verwerkt en gebruikt om voorspellingen te doen over toekomstig gedrag. Bekende voorbeelden van het toepassen van big data komen uit de marketing. Zo is het verhaal bekend van het Amerikaanse Target, dat door gegevens van klantenkaarten te analyseren, een tiener bestookte met gepersonaliseerde advertenties gericht op jonge moeders, nog voor ze haar ouders verteld had dat ze zwanger was. Of het voorbeeld waarbij zoektermen uit google gebruikt worden om met grote precisie de uitbraak van een griepepidemie te voorspellen. Naast deze verhalen zijn er ook veel voorbeelden waarmee we in ons dagelijks leven direct geconfronteerd worden, vaak zonder dat we het merken. Hoelang zal het nog duren voordat een machine stuk gaat? Is het verstandig om nu onderhoud te plegen, of kan dat nog jaren wachten? Welke combinaties van producten worden vaak gekocht en hoe gebruik ik deze informatie om mijn (digitale) winkel in te richten? Wat is interessante informatie om te posten op een website, zodat hij meer traffic genereert? Hoe kan informatie uit verschillende bronnen gecombineerd worden tot een accuraat reisadvies? Op de achtergrond draaien complexe algoritmes die verschillende databronnen integreren en analyseren en die voorspellingen doen omtrent gedrag.
Big data
‘Big data’ betekent meer dan alleen veel data. Een eenduidige definitie is alleen niet voorhanden. Vaak wordt ‘big data’ gekarakteriseerd door de 3 V’s (Gartner, 2018): Volume, Variety en Velocity. Volume slaat inderdaad op de omvang van de data, al wordt het ook geregeld geïnterpreteerd als dat wat er allemaal met de data gedaan kan worden. Variety benadrukt meer de diversiteit van de data. De data zijn vaak ongestructureerd en kunnen niet in standaard databases opgeslagen worden. De Velocity slaat ten slotte op de snelheid waarmee nieuwe data binnenkomen en/of opgevraagd worden. Een voorbeeld hierbij zijn socialmediadata. De omvang is enorm, de berichten zijn heel divers en er is een continue stroom data. Kenmerkend voor ‘big data’ is verder dat ze vragen om effectieve en innovatie vormen van informatieverwerking. Het doel is ten slotte om te komen tot een beter inzicht, betere besluitvorming en het automatiseren van processen. Een vierde V die geregeld aan de definitie toegevoegd wordt, staat voor Verocity, ofwel de ruis of de onzekerheid in de data, wanneer de afkomst en de kwaliteit van de data onbekend zijn. Als er aan deze kenmerken wordt voldaan, wordt er vaak gesproken over ‘big data’.
Big data in de wetenschap
Niet alleen bedrijven, maar ook wetenschappers maken in toenemende mate gebruik van die grote datamassa. Dat zie je terug in het aantal conferentiebijdrages en publicaties in internationale tijdschriften waarin ‘big data’ een rol speelt. Tot 2008 speelde big data bijna geen rol. Pas vanaf 2008 begint het aantal publicaties sterk te stijgen (zie Figuur 2). Inmiddels is het aantal vrij stabiel, rond de 3500 per jaar. Deze stijging is makkelijk te verklaren. Rond 2008 wordt het steeds makkelijker om gebruik te maken van die data. Nieuwe soorten data, zoals die van social media, die er vroeger niet waren, komen beschikbaar. Daardoor ontstaan nieuwe vragen en onderzoeksmogelijkheden. Ook nemen de mogelijkheden voor analyse sterk toe.

Toch kleven er wel risico’s aan het gebruik van big data. Ik noem er drie. Doordat wetenschappers niet langer de controle hebben over hun dataverzameling is er, bijvoorbeeld, minder aandacht voor het zorgvuldig opzetten van steekproeven. Het gevolg hiervan is dat de uitkomsten van een onderzoek minder goed gegeneraliseerd kunnen worden naar grotere populaties. Verder is meestal niet goed gedocumenteerd waar al de data precies vandaan komen en welke bewerkingen er inmiddels op zijn toegepast, waardoor de kwaliteit van de data onbekend is. Het gevolg hiervan is dat de betrouwbaarheid van de resultaten ter discussie staat. Ten slotte krijgen correlaties, een maat voor de samenhang van twee of meer variabelen, veel meer aandacht dan causaliteit. De waaromvraag, die vooral centraal stond in bijvoorbeeld de sociale wetenschappen, wordt vervangen door het ontdekken van patronen. Steeds vaker wordt gewerkt vanuit het adagium ‘Waar is wat werkt’. Vanwege al deze ontwikkelingen wordt daarom wel gesproken van een paradigmawisseling.
Big data-analytics
Hoe gaat dat nu in zijn werk, die bigdata-analytics? Laten we bijvoorbeeld kijken naar het gebruik van logfiles uit een elektronisch leersysteem. Binnen het basisonderwijs en het voortgezet onderwijs wordt steeds vaker gebruikgemaakt van software om leerlingen bepaalde kennis en vaardigheden bij te brengen. Een leerling maakt opgaven in een digitale omgeving. Een opgave wordt automatisch nagekeken en de leerling krijgt feedback of het antwoord goed of fout was. Via een dashboard houdt de docent het overzicht over de klas. Op basis van de prestaties kan de moeilijkheid van de opgaven aangepast worden aan het niveau van de leerling. Deze systemen kunnen gecombineerd worden met een klassikale instructie, maar de leerling kan ook individuele instructie ontvangen via een tablet of pc.
De logfiles van deze systemen bestaan uit regels tekst, nummers en symbolen, die aangeven wat een leerling concreet gedaan heeft, voorzien van een tijdstip. Als je deze code kunt ontcijferen, kun je bijvoorbeeld precies achterhalen wat de leerling heeft gedaan, waar hij/zij op heeft geklikt, hoe lang bepaalde informatie zichtbaar is geweest, hoe vaak de helpfunctie is geraadpleegd, hoe snel een vraag is beantwoord en hoe vaak het antwoord is gewijzigd. Omdat de logfiles alles wat een leerling doet opslaan, zijn ze vaak bijzonder groot (vandaar de naam big data) maar bevatten ze veel onbruikbare informatie. Met bigdata-analytics kan de bruikbare informatie gemakkelijk van de onbruikbare worden gescheiden, worden geanalyseerd en vertaald naar concrete acties.
Bij bigdata-analytics wordt een model ontwikkeld dat op basis van complexe, vaak ongeordende input een bekende outputvariabele zo goed mogelijk voorspelt. Dat wordt ook wel supervised learning genoemd. De alternatieve vorm, unsupervised learning, is vooral gericht op het vinden van samenhang en patronen tussen de inputvariabelen. Bij bigdata-analytics wordt de dataset vaak opgedeeld in een trainingset en een testset. Afhankelijk van de totale hoeveelheid data, wordt vaak gekozen voor een verhouding van zeventig procent trainingdata en dertig procent testdata. Het model wordt ontwikkeld voor de trainingset en vervolgens gevalideerd op de testset. De input van het model bestaat uit gestructureerde of ongestructureerde data. Bij gestructureerde data bestaat de input al uit getallen of scores op een vragenlijst. Bij ongestructureerde data moeten textminingtechnieken gebruikt worden om de data om te zetten in bruikbare variabelen. Dit proces wordt ook wel pre-processing genoemd. Tekstanalysesoftware kan automatisch hoofdletters verwijderen, getallen verwijderen, punctuatie verwijderen, namen herkennen en vervoegingen verwijderen.
Na de pre-processing worden variabelen afgeleid uit de voorbewerkte tekst. Daarbij kun je denken aan frequenties van woordgebruik, zinslengte, taalcomplexiteit of bijvoorbeeld het gegeven dat een zin een positief of een negatief sentiment heeft. In stap twee van het proces worden die variabelen, ook wel features genoemd, geselecteerd die in stap drie door het machinelearningalgoritme worden gebruikt om een accurate predictie van de output variabele, te geven. Bekende machinelearningalgoritmen zijn Naive Bayes (NB), Support Vector Machines (SVM) of Classification and Regression Trees (CART). Elk van deze methoden heeft zijn unieke manier om op basis van de inputvariabelen, de outputvariabele te voorspellen. CART resulteert in een beslisboom die goed te interpreteren is, terwijl SVM meer functioneert als een black box. Technisch gezien lijken de machinelearningmodellen veel op statistische modellen. Het grote verschil zit hem in de manier waarop de parameters in de modellen uitgerekend dan wel geschat worden.
Als het model getraind is, wordt het toegepast op de testset. Ten slotte wordt gecontroleerd of deze voorspelde output overeenkomt met de werkelijke waarde. Om de stabiliteit van de gevonden modellen te testen, wordt vaak gebruikgemaakt van kruisvalidatie. Daarvoor wordt de trainingset verdeeld in tien gelijke subsets. Vervolgens wordt de hierboven beschreven procedure tien keer uitgevoerd, waarbij telkens een model wordt gebouwd op een trainingset die bestaat uit negen van de tien subsets. Bij een stabiel probleem verschillen de tien modellen slechts marginaal. Als er sprake is van veel variatie, dan moet geconcludeerd worden dat de modellen niet stabiel genoeg zijn om tot een goede voorspelling te komen.
Maar wat levert dit ingewikkelde machinelearningproces ons nu op? Het is een alternatieve aanpak iets te meten wat we tot nu toe nauwelijks en/of alleen tegen hoge kosten boven tafel konden krijgen. Het kan bijvoorbeeld gebruikt worden om een antwoord te geven op de vraag welke bedrijven wellicht wel en welke bedrijven geen fraude plegen. Fissette (2017) laat zien hoe je met behulp van verschillende methodes frauduleuze bedrijven kunt onderscheiden van niet frauduleuze bedrijven door middel van het screenen van de managementsummary van hun jaarverslagen. Deze screening helpt accountants om te besluiten welke bedrijven grondiger ge-audit moeten worden dan andere.
Het toepassen van deze machinelearningmodellen kan alleen als er aan een aantal voorwaarden is voldaan. De belangrijkste voorwaarde is dat er een criterium aanwezig is en dat kan alleen als we een valide meting hebben van hetgeen we willen meten. Daarnaast is het soms nodig om data uit verschillende bronnen aan elkaar te koppelen. Veldkamp en de Vries (2008) beschrijven een onderzoek naar faillissementsfraude. Daarbij werd samengewerkt met het ministerie van Justitie, het Openbaar Ministerie en de politie Noord/Oost Nederland. Een gespecialiseerd rechercheteam had informatie verzameld over alle faillissementen waarbij op een of andere manier fraude was gepleegd. De vraag was of deze frauduleuze faillissementen met behulp van bigdata-analytics onderscheiden konden worden van faillissementen die schoon waren. Doordat gegevens over het bedrijf gekoppeld werden aan gegevens over ongewone financiële transacties, die weer gekoppeld werden aan gegevens van de bestuurders, die op hun beurt weer gekoppeld werden aan eventuele gegevens over het strafrechtelijke verleden van de bestuurders, kon een neuraal netwerk gefit worden dat meer dan dertig procent van de frauduleuze faillissementen herkende terwijl maar vier procent van de faillissementen ten onrechte als frauduleus werd geclassificeerd. In het onderzoek naar faillissementsfraude werden verschillende tekstbestanden aan elkaar gekoppeld. Wiegersma, Mink-Nijdam, van Hessen, Olff & Veldkamp, (2017) daarentegen voegden gegevens over spraak toe aan de transcripten van therapiesessies. Op die manier werd de tekst verrijkt met emotie, die af te leiden was uit volume, snelheid, pauzes en variatie in toonhoogte. Deze data hielpen om nauwkeuriger te analyseren wat er tijdens een therapiesessie gebeurde en op welke moment en hoe er doorbraken plaatsvonden.
Verder lezen?
De verdere inhoud van dit artikel of deze pagina is voorbehouden aan onze abonnees (u kunt hier inloggen).
Bent u nog geen abonnee, vraagt u dan een proefnummer aan, of registreert u zich direct online voor een abonnement.